Microsoft ends support for Internet Explorer on June 16, 2022.
We recommend using one of the browsers listed below.
- Microsoft Edge(Latest version)
- Mozilla Firefox(Latest version)
- Google Chrome(Latest version)
- Apple Safari(Latest version)
Please contact your browser provider for download and installation instructions.


June 1, 2026
NTT, Inc.
Why Did the AI Reach That Conclusion? NTT Establishes Multimodal XAI Technology for Explainable AI Inference
- Enhancing trust between humans and AI, and among AI systems, to enable reliable business decision-making and AI agent collaboration -
News Highlights:
- Identified a critical issue in which Large Vision-Language Models (LVLMs) generate final outputs that are not consistently grounded in their Chain-of-Thought (CoT) reasoning processes.
- Established "Rationale-Enhanced Decoding," a new decoding framework that enables LVLMs to generate outputs grounded in both visual inputs and rationales during inference without additional training.
- Demonstrated that the proposed technology enables previously black-box LVLMs to operate as explainable AI (XAI), supporting high-reliability applications such as business decision-making and AI agent collaboration.
TOKYO — June 1, 2026 — NTT, Inc. (Headquarters: Chiyoda-ku, Tokyo; President and CEO: Akira Shimada; hereinafter "NTT") has established Rationale-Enhanced Decoding, a new inference framework designed to improve the reliability of outputs generated by multimodal foundation models that process both images and language. The technology addresses a key issue in CoT reasoning by LVLMs: the tendency to ignore self-generated rationales. Unlike conventional inference methods, the proposed approach separately performs image-based inference and rationale-based inference, then combines them through ensemble decoding. This enables the model to generate responses grounded in information derived from both visual inputs and rationales.
This research will be presented at the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2026(*1), one of the world's premier international conferences in the field of computer vision, to be held in Denver, Colorado, USA, from June 3 to June 7, 2026.
Background
In recent years, the development of Large Vision-Language Models (LVLMs), which integrate Large Language Models (LLMs) with pretrained image encoders, has significantly advanced multimodal reasoning capabilities. Unlike text-only LLMs, LVLMs can directly process visual inputs in addition to text, enabling their use as a foundation for complex multimodal reasoning tasks based on visual content, such as video analysis and document understanding, which are difficult to address using text alone.
Similar to LLMs that operate solely on text inputs, Chain-of-Thought (CoT) reasoning has also been regarded as an effective approach for improving inference performance and enabling explainable reasoning in LVLMs. In CoT reasoning, the model first generates intermediate rationales from visual and textual inputs, then appends those rationales to the input sequence to produce a final answer.
However, existing CoT mechanisms generate final outputs by processing images and rationales as a single combined sequence. As a result, they lack a causal structure that ensures the information contained in the rationales is actually used in generating the output, leaving the use of rationales entirely dependent on the model itself. In other words, CoT-based final outputs are not guaranteed to be grounded in the generated rationales (Figure 1).
Through experiments and analysis, it was found that existing LVLMs can generate final answers while ignoring the content of their own generated rationales during multimodal CoT reasoning. For example, even when the rationale is replaced with content unrelated to the question, the model's final output may remain unchanged (Figure 2). In one such example, a rationale describing an unrelated sports car was provided alongside an image of a presentation slide document. Despite the irrelevant rationale, the model generated the same answer as when the correct rationale was provided, rather than producing the incorrect answer implied by the substituted rationale. In this case, the model is considered to have generated the final output solely from the image, meaning the rationale cannot be interpreted as an explanation for the output.
These findings reveal a fundamental limitation of conventional LVLM inference: consistency between rationales and final answers is not guaranteed, preventing truly explainable reasoning.
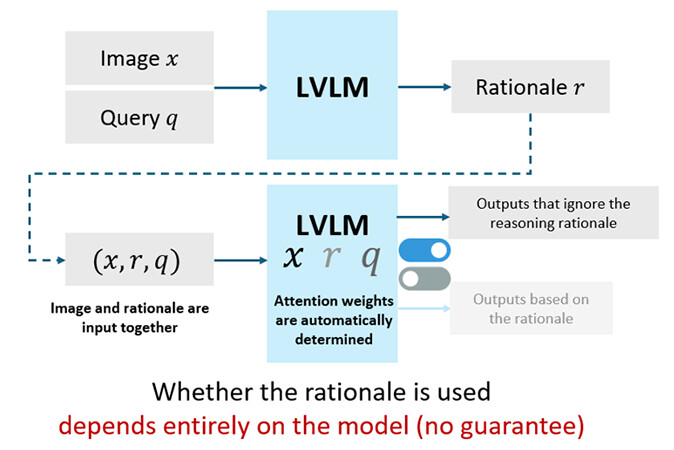 Figure 1. CoT Reasoning in LVLMs
Figure 1. CoT Reasoning in LVLMs
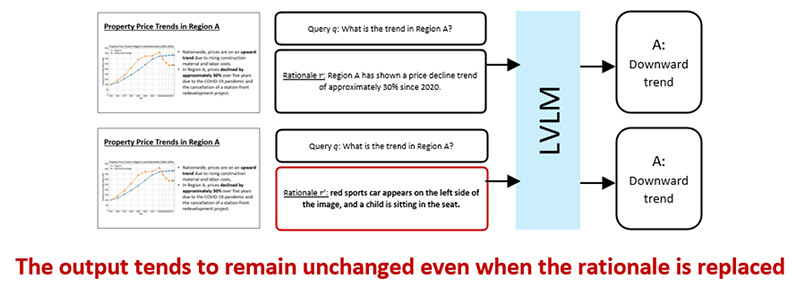 Figure 2. Lack of Dependence on Rationales in LVLMs
Figure 2. Lack of Dependence on Rationales in LVLMs
Research Overview
To address this issue, this research revisited the inference mechanism of existing LVLMs and established Rationale-Enhanced Decoding, a plug-and-play decoding technique that operates at inference time without requiring additional datasets or costly retraining.
Rationale-Enhanced Decoding separates the probability distribution used by an LVLM to predict the next token into two components: a distribution conditioned on the image and a distribution conditioned on the rationale. These distributions are then combined multiplicatively to harmonize information derived from visual inputs and rationales when generating responses (Figure 3). Because the image and rationale are independently provided to the LVLM in this framework, outputs can be explicitly grounded in the rationale.
More specifically, multimodal CoT reasoning is formulated as a KL divergence-constrained reward maximization problem, where the log-likelihood of the rationale-conditioned distribution serves as the reward function. By solving this optimization problem in closed form, the proposed method enables LVLMs to generate next-token predictions grounded in both visual information and rationales using inference-time computation alone (Figure 4).
Technical Highlights
(1) Formulating Multimodal CoT as a KL Divergence-Constrained Reward Maximization Problem
This research first focused on the fact that conventional multimodal CoT reasoning relies on a single next-token prediction distribution jointly conditioned on both the image and the rationale. As a result, the generated response is not necessarily guaranteed to be grounded in the rationale itself.
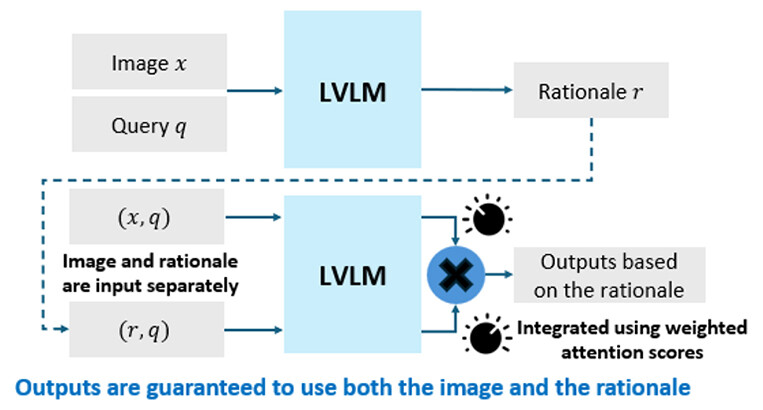 Figure 3. Overview of Rationale-Enhanced Decoding
Figure 3. Overview of Rationale-Enhanced Decoding
 Figure 4. Reformulation as a Reward Maximization Problem
Figure 4. Reformulation as a Reward Maximization Problem
To enable reasoning explicitly based on both visual inputs and rationales, the inference process was reformulated as a new optimization problem. Specifically, token generation is performed by maximizing the prediction probability conditioned on the rationale as a "reward," while simultaneously constraining the prediction distribution so that it does not deviate excessively from the distribution conditioned on the image through a KL divergence constraint (Figure 4, top).
(2) Plug-and-Play Implementation Without Additional Training
Although the optimization problem described above could theoretically be solved through additional training of the LVLM, doing so would require substantial costs in terms of training datasets and computational resources.
To address this challenge, this research mathematically proved that the optimal solution to the optimization problem is equivalent to a distribution represented by the product of the image-conditioned distribution and the rationale-conditioned distribution (Figure 4, bottom). As a result, the actual implementation only requires calculating a weighted sum of the logits produced by the model, eliminating the need for any additional training. This makes the proposed method highly practical as a plug-and-play approach that can be directly integrated into any existing LVLM.
Experimental results demonstrated that applying Rationale-Enhanced Decoding consistently achieved substantial improvements in reasoning performance, including answer accuracy, across a wide range of LVLMs. Furthermore, when higher-quality rationales, such as rationales generated by OpenAI's GPT-4, were provided, the effectiveness of Rationale-Enhanced Decoding was further amplified. These results demonstrate that LVLMs equipped with the proposed method can faithfully interpret and utilize the content of rationales.
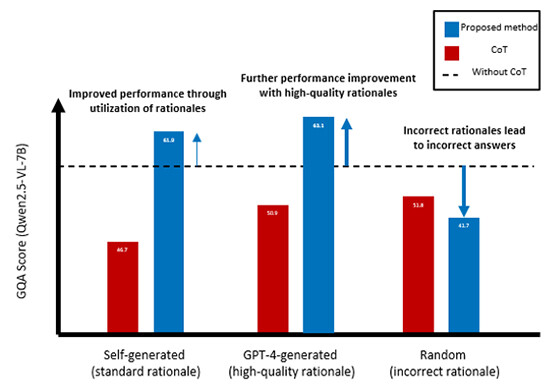 Figure 5. Results of the Rationale Intervention Experiment
Figure 5. Results of the Rationale Intervention Experiment
 Figure 6. Example of Inference Generated by the Proposed Method. The image is sourced from:
Figure 6. Example of Inference Generated by the Proposed Method. The image is sourced from:Hudson, Drew A., and Christopher D. Manning. "Gqa: A new dataset for real-world visual reasoning and compositional question answering." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019.
Future Outlook
This research established Rationale-Enhanced Decoding, a new inference framework that generates final responses by explicitly utilizing both visual inputs and rationales. The study also confirmed that the proposed method can significantly improve both rationale faithfulness and reasoning performance across a wide range of LVLMs without requiring additional training.
The technology demonstrates the potential to introduce interpretability into the reasoning processes of LVLMs, which have traditionally operated as black-box systems. As a result, the technology is expected to accelerate the deployment of LVLMs in fields that require highly reliable inference systems, including medical image diagnosis and conversational agents supporting critical human decision-making.
NTT will continue advancing next-generation technologies that improve AI reliability and contribute to the realization of AI Constellation(*2), in which large numbers of AI systems collaborate seamlessly.
Presentation Information
This research will be presented at CVPR 2026 (Conference on Computer Vision and Pattern Recognition), one of the premier international conferences in computer vision, to be held from June 3 to 7, 2026, under the following title and authorship.
Authors:
Shin'ya Yamaguchi and Daiki Chijiwa, NTT Computer & Data Science Laboratories
Kosuke Nishida, NTT Human Informatics Laboratories
[Glossary]
(*1)CVPR 2026
CVPR is one of the top international conferences in the field of computer vision.
CVPR 2026 Official Website: https://cvpr.thecvf.com/![]()
(*2)AI Constellation
https://www.rd.ntt/e/cds/ai-constellation/![]()
About NTT
NTT is a leading global technology innovator, providing a broad range of services to both consumers and businesses. As a mobile operator and provider of infrastructure, networks, and services, NTT is dedicated to promoting a sustainable future through cutting-edge innovations. Our portfolio includes business consulting, AI-powered solutions, application services, global networks, cybersecurity, data center and edge computing, all supported by our deep global industry expertise. Generating over $90 billion in revenue and employing 340,000 professionals, we allocate 30% of our annual profits to fundamental research and development. With operations spanning more than 70 countries and regions, our clients include over 75% of Fortune Global 100 companies, alongside thousands of enterprises, government organizations, and millions of consumers.
Media Contact
NTT, Inc.
NTT Service Innovation Laboratory Group
Public Relations
Inquiry Form![]()
Information is current as of the date of issue of the individual press release.
Please be advised that information may be outdated after that point.




NTT STORY
WEB media that thinks about the future with NTT